如何编写一个好的 CLAUDE.md
注意:本文同样适用于 AGENTS.md,这是 CLAUDE.md 的开源等效文件,适用于 OpenCode、Zed、Cursor 和 Codex 等代理和工具。
原则:LLMs(基本上)是无状态的
LLMs 是无状态函数。它们的权重在用于推理时是冻结的,因此它们不会随时间学习。模型对你的代码库唯一了解的就是你输入给它的 tokens。
类似地,像 Claude Code 这样的编码代理工具通常需要你显式管理代理的记忆。CLAUDE.md(或 AGENTS.md)是默认情况下唯一会进入你与代理的每一次对话的文件。
这有三个重要含义:
- 编码代理在每个会话开始时对你的代码库一无所知。
- 代理必须在每次启动会话时被告知关于代码库的任何重要信息。
- CLAUDE.md 是实现这一点的首选方式。
CLAUDE.md 让 Claude 了解你的代码库
由于 Claude 在每个会话开始时对你的代码库一无所知,你应该使用 CLAUDE.md 来引导 Claude 了解你的代码库。在高层次上,这意味着它应该涵盖:
- 是什么(WHAT):告诉 Claude 关于技术栈、项目结构。给 Claude 一张代码库地图。 这在 monorepos 中尤其重要!告诉 Claude 有哪些应用、有哪些共享包,以及每个部分的用途,这样它就知道在哪里查找内容
- 为什么(WHY):告诉 Claude 项目的目的以及仓库中所有内容的作用。项目不同部分的目的和功能是什么?
- 如何(HOW):告诉 Claude 应该如何在项目上工作。例如,你使用 bun 而不是 node?你需要包含它实际完成有意义工作所需的所有信息。Claude 如何验证它的更改?它如何运行测试、类型检查和编译步骤?
但你的做法很重要!不要试图把 Claude 可能需要运行的每个命令都塞进你的 CLAUDE.md 文件——你会得到次优结果。
Claude 经常忽略 CLAUDE.md
无论你使用哪个模型,你可能会注意到 Claude 经常忽略你的 CLAUDE.md 文件的内容。
你可以通过使用 ANTHROPIC_BASE_URL 在 claude code CLI 和 Anthropic API 之间放置一个日志代理来自己调查这一点。Claude code 在用户消息中注入以下系统提醒和你的 CLAUDE.md 文件:
<system-reminder>
IMPORTANT: this context may or may not be relevant to your tasks.
You should not respond to this context unless it is highly relevant to your task.
</system-reminder>因此,如果 Claude 认为它与当前任务无关,它将忽略你的 CLAUDE.md 的内容。文件中包含的与你正在处理的任务不普遍适用的信息越多,Claude 忽略文件中指令的可能性就越大。
为什么 Anthropic 添加了这个?很难确切地说,但我们可以推测一下。我们遇到的大多数 CLAUDE.md 文件都包含一堆并不广泛适用的指令。许多用户将该文件视为一种向他们不喜欢的行为添加"热修复"的方式,通过附加许多不一定广泛适用的指令。
我们只能假设 Claude Code 团队发现,通过告诉 Claude 忽略不好的指令,工具实际上产生了更好的结果。
创建一个好的 CLAUDE.md 文件
以下部分提供了一些关于如何遵循上下文工程最佳实践编写好的 CLAUDE.md 文件的建议。
你的使用情况可能有所不同。并非所有这些规则都一定适用于每个设置。像其他任何事情一样,当你满足以下条件时,可以随意打破规则:
- 你理解何时以及为什么可以打破它们
- 你有充分的理由这样做
指令越少越好
把 Claude 可能需要运行的每一个命令,以及你的代码标准和风格指南都塞进 CLAUDE.md 可能很诱人。我们不建议这样做。
虽然这个话题没有以非常严格的方式进行调查,但已经进行了一些研究,表明以下内容:
- 前沿思维型 LLMs 可以以合理的一致性遵循约 150-200 条指令。较小的模型可以处理的指令比较大的模型少,非思维型模型可以处理的指令比思维型模型少。
- 较小的模型变得更差,速度也更快。具体来说,随着指令数量的增加,较小的模型往往表现出指数衰减的指令遵循性能,而较大的前沿思维型模型表现出线性衰减(见下图)。因此,我们建议不要在多步骤任务或复杂的实现计划中使用较小的模型。
- LLMs 偏向于提示边缘的指令:在最开始(Claude Code 系统消息和 CLAUDE.md),以及在最后(最近的用户消息)
- 随着指令数量的增加,指令遵循质量均匀下降。这意味着当你给 LLM 更多指令时,它不会简单地忽略较新的(“文件中更靠下的”)指令——它开始均匀地忽略所有指令
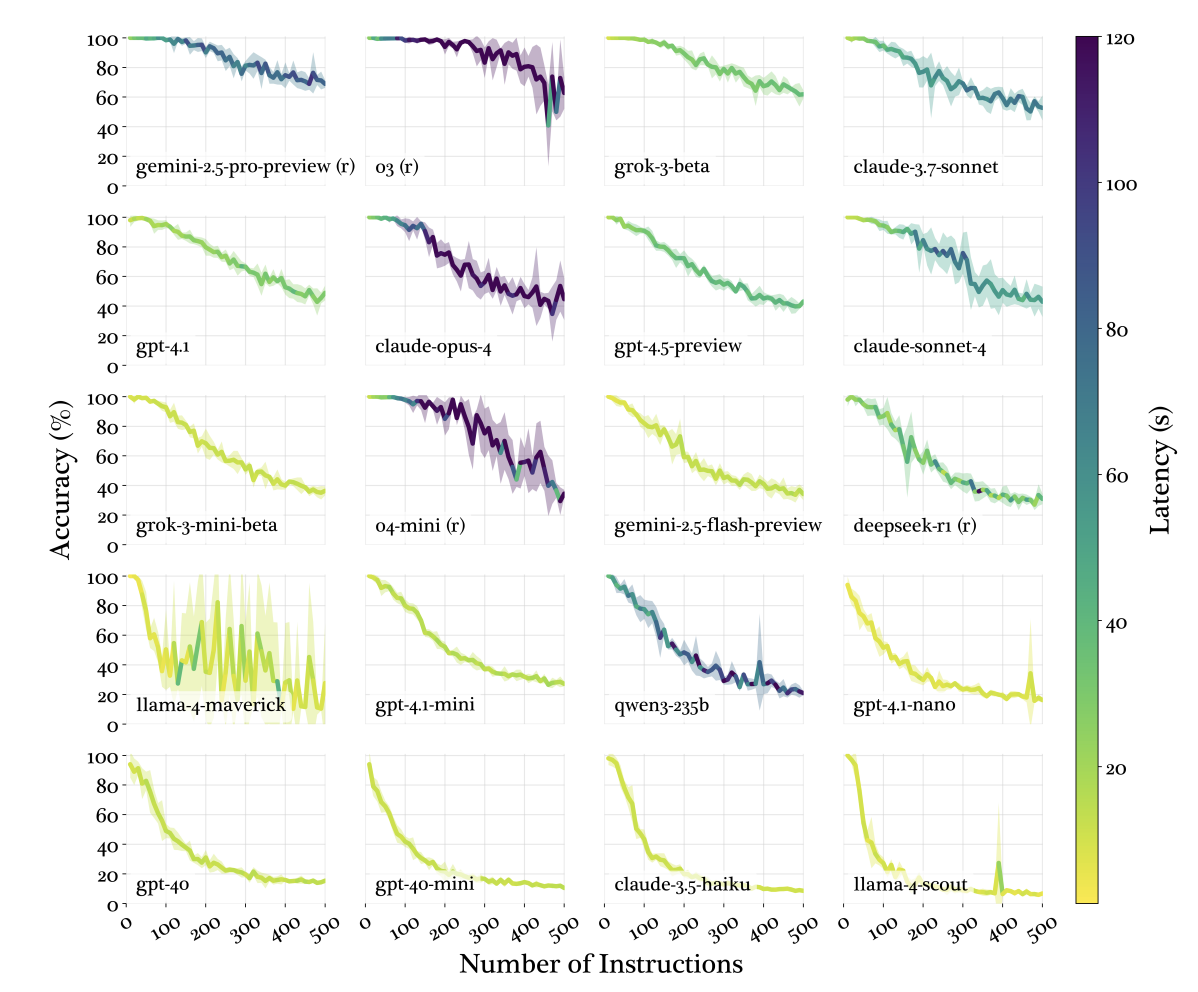
我们对 Claude Code 工具的分析表明,Claude Code 的系统提示包含约 50 条单独的指令。根据你使用的模型,这已经是你的代理可以可靠遵循的指令的近三分之一——这还是在规则、插件、技能或用户消息之前。
这意味着你的 CLAUDE.md 文件应该包含尽可能少的指令——理想情况下只包含普遍适用于你任务的指令。
CLAUDE.md 文件长度和适用性
在其他条件相同的情况下,当 LLM 的上下文窗口充满了集中、相关的上下文(包括示例、相关文件、工具调用和工具结果)时,它在任务上的表现会比上下文窗口有很多不相关上下文时更好。
由于 CLAUDE.md 会进入每一个会话,你应该确保其内容尽可能普遍适用。
例如,避免包含关于(例如)如何构建新数据库模式的指令——当你在处理其他不相关的事情时,这不会有影响,反而会分散模型的注意力!
在长度方面,“少即是多"的原则同样适用。虽然 Anthropic 没有关于 CLAUDE.md 文件应该多长的官方建议,但普遍共识是 < 300 行最好,更短更好。
在 HumanLayer,我们的根 CLAUDE.md 文件不到 60 行。
渐进式披露
编写一个简洁的 CLAUDE.md 文件来涵盖你想让 Claude 知道的所有内容可能具有挑战性,尤其是在较大的项目中。
为了解决这个问题,我们可以利用渐进式披露原则,确保 Claude 只在需要时才看到特定于任务或项目的指令。
我们建议不要在 CLAUDE.md 文件中包含关于构建项目、运行测试、代码约定或其他重要上下文的所有不同指令,而是将特定于任务的指令保存在项目中某处具有自描述名称的单独 markdown 文件中。
例如:
agent_docs/
|- building_the_project.md
|- running_tests.md
|- code_conventions.md
|- service_architecture.md
|- database_schema.md
|- service_communication_patterns.md然后,在你的 CLAUDE.md 文件中,你可以包含这些文件的列表以及每个文件的简要描述,并指示 Claude 决定哪些(如果有)是相关的,并在开始工作之前读取它们。或者,要求 Claude 首先向你展示它想要读取的文件以供批准,然后再读取它们。
**优先选择指针而不是副本。**如果可能,不要在这些文件中包含代码片段——它们会很快过时。相反,包含文件:行引用以将 Claude 指向权威上下文。
从概念上讲,这与 Claude Skills 的预期工作方式非常相似,尽管技能更侧重于工具使用而不是指令。
Claude 不是一个昂贵的 linter
我们看到人们在 CLAUDE.md 文件中放置的最常见的内容之一是代码风格指南。永远不要让 LLM 去做 linter 的工作。与传统的 linters 和格式化工具相比,LLMs 相对昂贵且速度极慢。我们认为你应该始终尽可能使用确定性工具。
代码风格指南不可避免地会在你的上下文窗口中添加一堆指令和大部分不相关的代码片段,降低你的 LLM 的性能和指令遵循,并占用你的上下文窗口。
LLMs 是上下文学习者!如果你的代码遵循某组风格指南或模式,你应该发现,有了代码库的一些搜索(或一个好的研究文档!),你的代理应该倾向于遵循现有的代码模式和约定,而无需被告知。
如果你对此感觉非常强烈,你甚至可以考虑设置一个 Claude Code Stop hook,运行你的格式化程序和 linter,并将错误呈现给 Claude 以供其修复。不要让 Claude 自己查找格式问题。
额外积分:使用可以自动修复问题的 linter(我们喜欢 Biome),并仔细调整你的规则,了解什么可以安全地自动修复,以实现最大(安全)覆盖。
你还可以创建一个 Slash Command,其中包含你的代码指南,并将 Claude 指向版本控制中的更改,或你的 git status,或类似的内容。这样,你可以分别处理实现和格式化。因此,你将看到两者都有更好的结果。
不要使用 /init 或自动生成你的 CLAUDE.md
Claude Code 和其他使用 OpenCode 的工具都有自动生成 CLAUDE.md 文件(或 AGENTS.md)的方法。
因为 CLAUDE.md 会进入 Claude code 的每一个会话,它是工具的最高杠杆点之一——无论好坏,取决于你如何使用它。
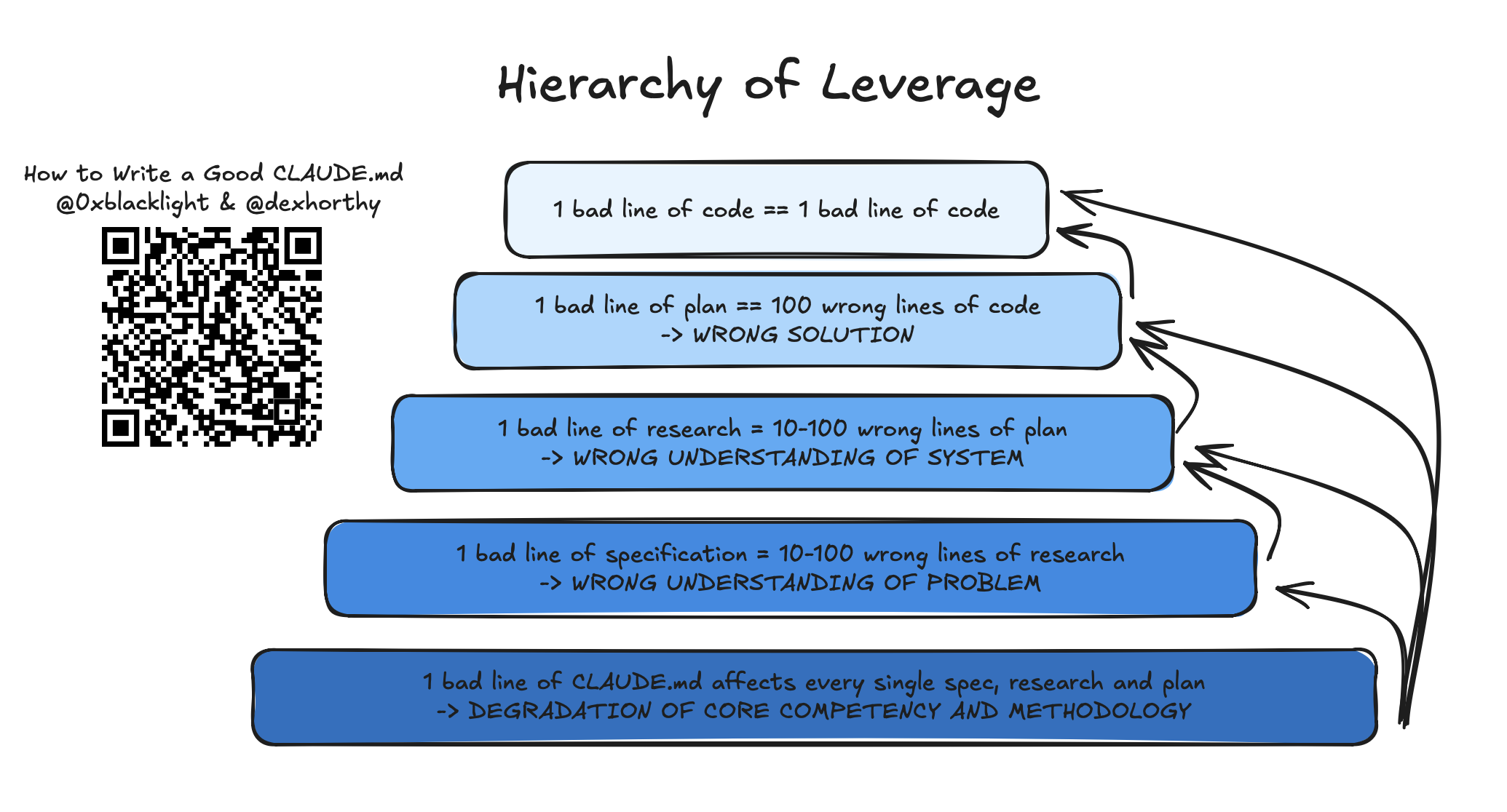
一行糟糕的代码就是一行糟糕的代码。实现计划中的一行错误有可能创建很多行糟糕的代码。误解系统工作方式的研究中的一行错误有可能导致计划中的很多错误行,因此作为结果产生更多错误代码行。
但 CLAUDE.md 文件影响你工作流程的每一个阶段以及它产生的每一个工件。因此,我们认为你应该花一些时间非常仔细地考虑其中的每一行:
结论
- CLAUDE.md 用于让 Claude 了解你的代码库。它应该定义你项目的为什么(WHY)、是什么(WHAT)和如何做(HOW)。
- 指令越少越好。虽然你不应该省略必要的指令,但你应该在文件中包含尽可能少的指令。
- 保持 CLAUDE.md 的内容简洁且普遍适用。
- 使用渐进式披露——不要告诉 Claude 你可能希望它知道的所有信息。相反,告诉它如何找到重要信息,以便它可以找到并使用它,但只在需要时使用,以避免占用你的上下文窗口或指令计数。
- Claude 不是 linter。使用 linters 和代码格式化程序,并根据需要使用 Hooks 和 Slash Commands 等其他功能。
- CLAUDE.md 是工具的最高杠杆点,因此避免自动生成它。你应该仔细制作其内容以获得最佳结果。